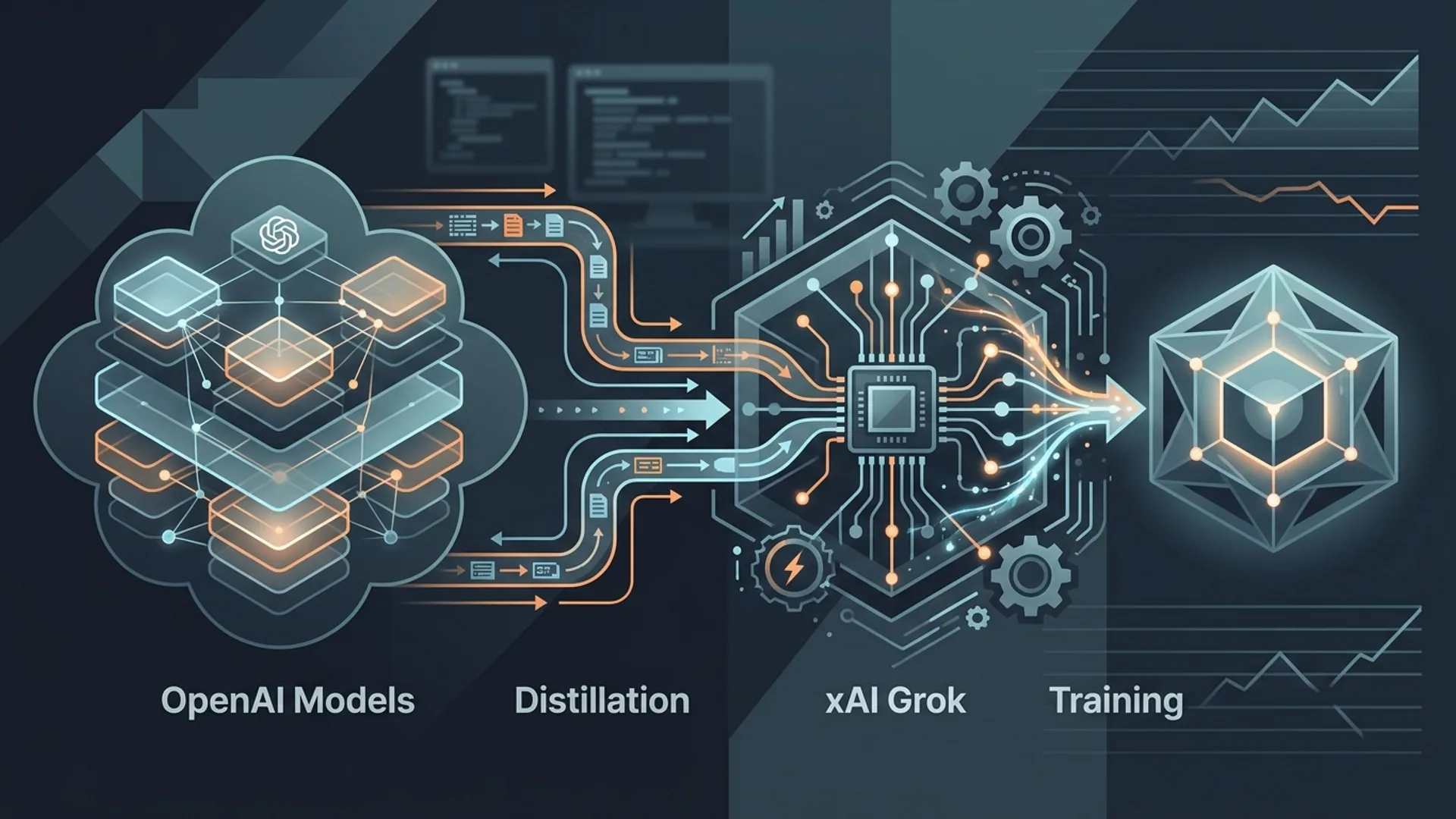
Elon Musk Confirms xAI Used OpenAI Models to Train Grok
Back in April 2026 during federal court testimony, Elon Musk dropped a bombshell for AI folks: xAI trained Grok by distilling OpenAI’s GPT-5 model. This isn’t rumor - it’s firsthand, legal-level confirmation of the exact engineering behind Grok’s competitive edge.
The takeaway? You don’t have to reinvent everything from scratch. Smart use of distillation plus real-time social data integration from X (formerly Twitter) gave Grok a huge leg up in both cost and performance. If you’re building AI products, this plays out like a blueprint.
What Is the Grok Language Model?
Grok is xAI’s AI chat system. Here’s the core: it blends distilled smarts from OpenAI models with real-time signals from X. That combo keeps Grok sharp, up-to-date, and way more affordable than simply calling GPT-5 directly.
Lean, fast, tuned for social relevancy - anyone shipping conversational agents will appreciate how this makes an AI not just smart but contextually alive.
Elon Musk’s Federal Court Testimony Details
Musk’s courtroom statement was straightforward: xAI used model distillation, a teacher-student training method. GPT-5 acted as the teacher, generating outputs for prompts. Then, those prompt-response pairs became the training data for Grok’s smaller, specialized models.
No hand-waving here. It’s proven engineering to accelerate development and slash computational expense without relinquishing the original model’s capabilities.
The process:
- GPT-5 generates outputs for a battery of prompts.
- Those serve as labeled data.
- Grok fine-tunes on this dataset, capturing GPT-5 prowess minus the bulk.
This shortcut isn’t some hack; it’s the secret sauce behind Grok’s rapid launch and lean cost structure.
Definition: Model Distillation
Model distillation is not a buzzword. It’s a tested engineering method where a smaller "student" model learns to replicate a larger "teacher" model’s outputs. Rather than training on raw data, the student mimics teacher predictions, yielding a compact, cheaper, and faster model.
What Model Distillation Means in Frontier AI Labs
Distillation is standard practice for teams pushing practical AI, even if outsiders misunderstand it. This isn’t cheating - it’s engineering efficiency at its finest.
GPT-5 churns out millions of response pairs, a vast knowledge base. Grok’s student models soak these in, trading raw scale for smart compression. The result: models that run faster, cost less, and can be tuned to specific domains.
If you’ve got more startup grit than resources, distillation lets you cut months off timelines, slash hosting bills, and create AI laser-focused on your user’s exact needs.
Key Benefits of Model Distillation:
- Cost efficiency: GPT-5 input tokens run about $150 per million; Grok 4.1’s distilled fast mode hits $0.20 per million. That’s 750x cheaper.
- Speed: Distilled models infer 40% faster, crucial when latency kills experience.
- Domain tuning: Distilled models plug in niche data easily, like scraping real-time X feeds, sharpening relevance.
Real Stats: Grok vs OpenAI’s Latest Models
| Metric | Grok 4 | OpenAI GPT-5 | Notes |
|---|---|---|---|
| 2025 AIME Math Competition | 93.3% | 79% | Grok outperforms GPT-5 by 14.3 points |
| Input Token Cost (per million) | $0.20 | $150 | Grok is 750x cheaper on input tokens |
| Output Token Cost (per million) | $0.50 | $600 | Grok is 1,200x cheaper on output |
| Latency Reduction | ~40% faster inference | Base model latency | Distillation reduces latency significantly |
(Sources: DataStudios.org, Solvimon.com)
Side note: Seeing a startup hit these numbers in a courtroom? That’s proof the economic advantage here isn’t theoretical.
How Grok Combines Distilled Knowledge with Real-Time Data
Here’s where Grok really outsmarts GPT-5-based competitors: real-time social feed digestion. Grok taps live data from X to keep language current, spot breaking news, and flex tone based on what’s trending right now.
Static benchmarks matter, but freshness and context are what actually make users engage daily. Grok’s hybrid model design - distilled base plus live streaming data - is a playbook every AI company should steal.
Ethical and Legal Considerations Around Model Reuse
Distilling OpenAI’s tech raises tough legal questions around intellectual property and fair use. Musk’s testimony happened amid tense lawsuits between nonprofit AI groups and startups leveraging their tech.
Distillation sits in a legal gray zone: engineers accept it as fair, but policy hasn’t caught up. For founders, the message is clear:
- Check licenses meticulously - some API terms explicitly restrict distillation.
- Build your own data and tuning on top to differentiate your product.
- Steel yourself for evolving legal battles.
This is a strategic risk, not a technical one.
AI 4U’s Perspective: Engineering Distillation the Right Way
We’ve been through this grind ourselves, chopping monthly inference from over $10k down to around $2k - without degrading quality.
Distillation requires more than flipping a switch:
- You pick prompts that truly represent your problem space.
- You validate the teacher’s responses carefully - garbage in, garbage out.
- You fine-tune and verify the student model relentlessly.
Here’s a practical snippet for pulling teacher outputs and starting fine-tuning:
javascriptLoading...
Running hundreds or thousands of prompts like this builds a robust dataset to distill knowledge effectively.
What This Means for AI Founders and CTOs
Building a large foundational model from scratch? Expect years and millions. Distillation lets you ship scalable, high-quality AI in months at pennies compared to direct GPT-5 use.
Some numbers here:
- Monthly distillation inference costs $2k–$5k vs. $10k+ calling GPT-5 directly.
- Focus your distillation prompts on domain-specific data to maximize accuracy and avoid wasting tokens.
- Use a hybrid approach: distilled backbone plus live data, the winning combo for relevance.
Ignore this approach, and you’ll either blow your budget or fall behind.
Get your distillation pipeline in place now.
Summary and Future Outlook
Musk’s court testimony shifted the AI startup playbook by confirming xAI built Grok through distilling GPT-5. This strategy slashes costs and latency yet retains competitive quality.
Add live social data, and you get a truly modern AI product with fresh context baked in - something static large models can’t match.
The next wave of startups will adopt this strategy en masse, sparking more innovation - legal frameworks will lag, but those who invest in smart distillation and domain tuning will lead.
Frequently Asked Questions
Q: What exactly is model distillation in AI?
A: Distillation is when a smaller AI model (student) learns to mimic a larger, costly teacher model by training on its output responses instead of raw data. The shortcut: cheaper, faster AI.
Q: How is Grok’s performance compared to OpenAI’s GPT-5?
A: Grok 4 nailed 93.3% on the 2025 AIME math competition - well above GPT-5’s 79%. It’s a win on both accuracy and cost fronts.
Q: Can startups legally use distillation on OpenAI models?
A: Legality depends on license terms and service agreements. Distillation sits in a regulatory gray zone but is a common engineering practice. Full compliance checks are essential.
Q: How much can distillation reduce AI inference costs?
A: Distillation can cut your inference spend by a factor of five or more. Grok’s input token cost runs at $0.20 per million versus GPT-5’s $150.
Thinking about building with Grok and distillation? AI 4U has production-ready AI apps in 2–4 weeks.
References
- Elon Musk testimony on xAI and distillation, TechCrunch, April 2026: https://techcrunch.com/2026/04/elon-musk-xai-openai-distillation/
- Forbes explainer on model distillation: https://forbes.com/ai/model-distillation
- Grok vs GPT-5 AIME results, DataStudios.org, 2025: https://datastudios.org/benchmarks/grok-vs-gpt5
- Grok pricing comparison, Solvimon.com, 2026: https://solvimon.com/pricing/grok-vs-openai
- Real-time data integration in Grok, SingularityMoments.com, 2026: https://singularitymoments.com/grok-xai-real-time-x